

BioByte 057: Why invest in biotech, astrocytes in neuroinflammation, comp bio for novel CRISPR variants, life-extension drugs nearing approval
BioByte 057: Why invest in biotech, astrocytes in neuroinflammation, comp bio for novel CRISPR variants, life-extension drugs nearing approval




Welcome to Decoding Bio, a writing collective focused on the latest scientific advancements, news, and people building at the intersection of tech x bio. If you’d like to connect or collaborate, please shoot us a note here or chat with us on Twitter: @zahrakhwaja @ameekapadia @ketanyerneni @morgancheatham @pablolubroth @patricksmalone. Happy decoding!

On a cold, crisp autumnal (yes I’m British) day, your weekly round up of hot tech bio papers, blogs and deals.
Computational Bio X CRISPR: Deep terascale clustering to uncover more than 200 new functional systems linked to CRISPR. These discoveries may help to further improve DNA- and RNA-editing technologies.
Life-extension drugs: Loyal announced FDA approval of their efficacy package which shows regulator confidence in their approach for extending canine lifespan with a newly developed drug
Astrocytes in Neuro-inflammation: Translating astrocyte neurobiology into novel drugs provides an interesting approach to tackling neurodegeneration.
Cradle.bio: Perspectives on biotech saas business models

What we read
Blogs
Latent optima [Alex Telford, November 2023]
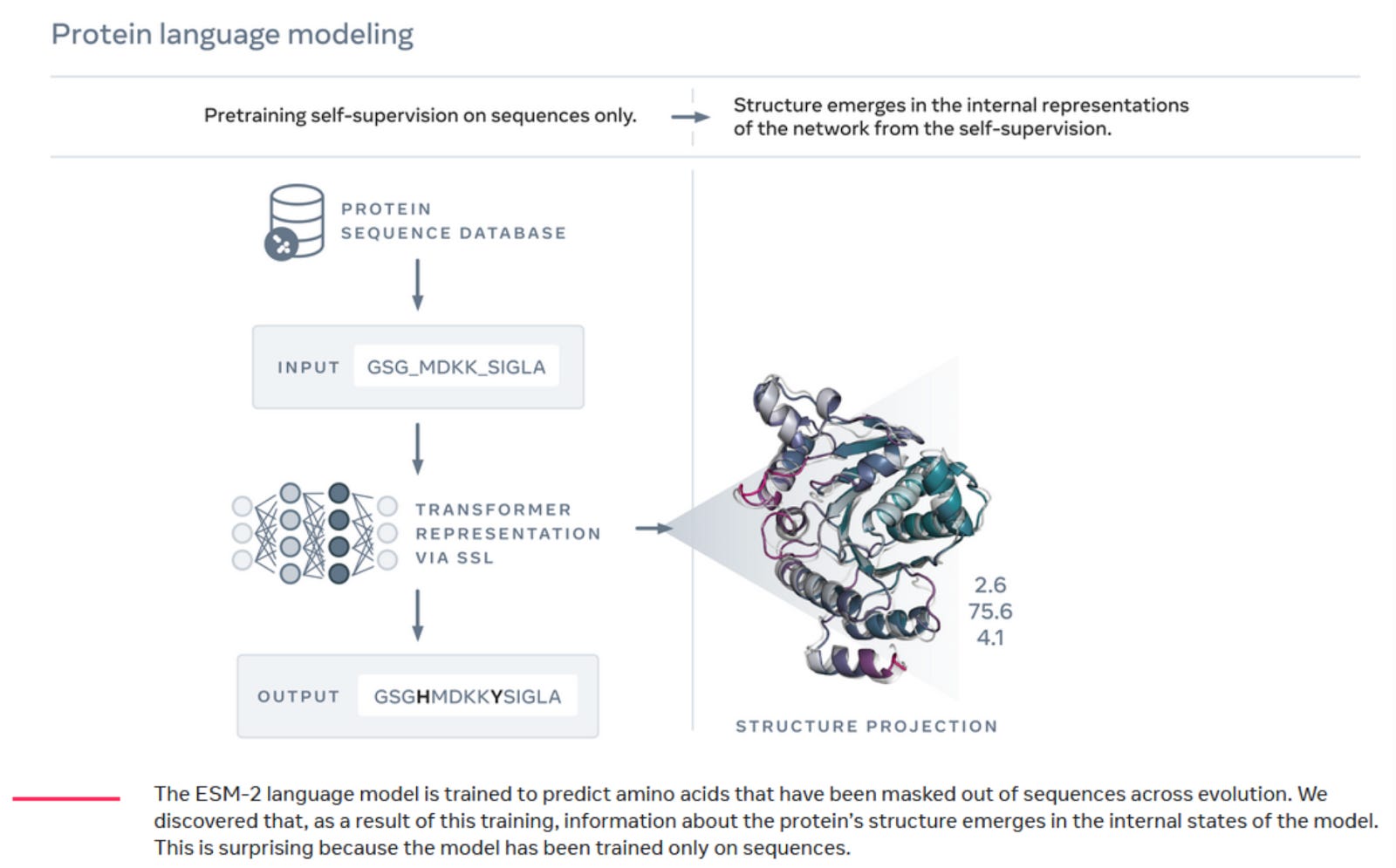
Latent information is information that is implicitly contained within data, but is not directly observable. This concept is core to machine learning, where ML models often infer latent features from raw data to make predictions or understand complex phenomena. In a new essay, Alex Telford extends this concept to biology. The essay delves into how organisms, like fish and birds, can be seen as embodied statistical models of their environments, driven by natural selection.
These concepts also help understand how protein language models like Meta’s ESMfold work. Despite being trained only on protein sequence data, ESMfold accurately predicts protein structures because the sequence data inherently contains information about protein folding processes. Protein folding and other biological processes have been optimized by natural selection, and therefore can be thought of as optimization functions. Alex argues for leveraging latent information in biological datasets as a powerful tool in generating optimization functions validated by millions of years of evolution. The successful use of ESMfold to enhance the properties of monoclonal antibodies is a recent example of the power of this approach.
A Life-Extension Drug for Big Dogs is Getting Closer to Reality [Emily Mullin, Wired, November 2023]
Earlier this week, San Francisco-based biotech company Loyal announced FDA approval of their efficacy package which shows regulator confidence in their approach for extending canine lifespan with a newly developed drug. Loyal has been designing this experimental drug to extend the lifespan and health of dogs by lowering growth hormone IGF-1 that is involved in dictating dog size. There is research showing dog size can affect longevity and in fact mix-breed dogs live longer on average than pure-bred dogs. Studies show that inhibiting this hormone can help increase longevity and in humans, a mid-range is ideal as extremes on either side are tied to increased risk of mortality. Thus far, Loyal has tested the injectable drug on 130 dogs showing that the hormone range for large dogs can be brought down to levels seen in mid-size dogs. With the support of the FDA, the company plans to launch a much larger trial of 1000 dogs aged 7+ years in the next year with hopes to have a drug on the market in 2026.
Why invest in biotech? [Stifel, November 2023]

Academic papers
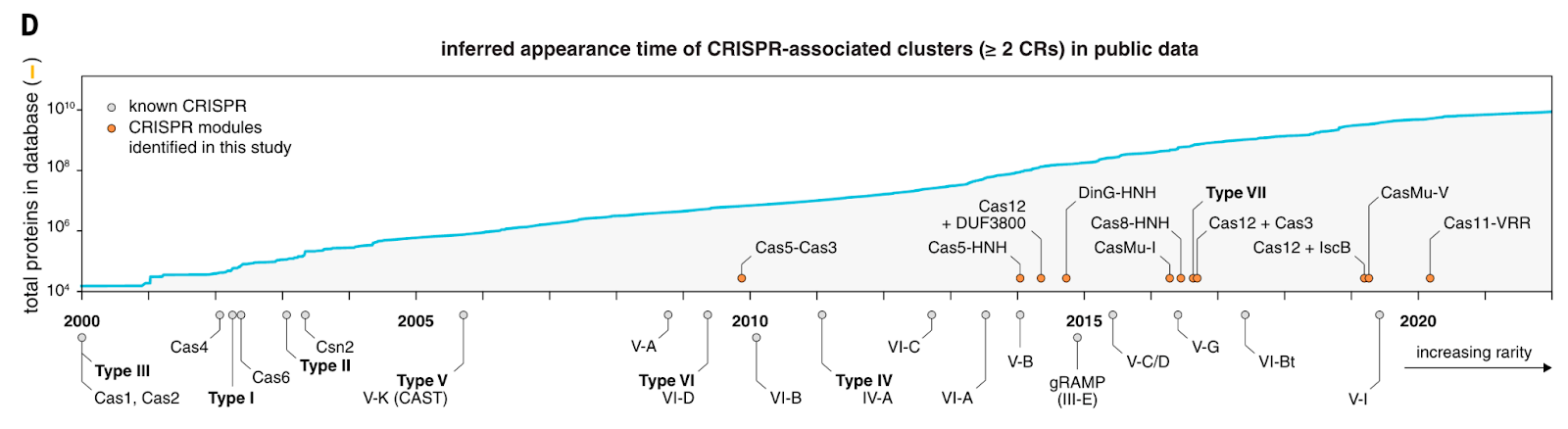
Uncovering the functional diversity of rare CRISPR-Cas systems with deep terascale clustering [Altae-Tran, Science, November 2023]
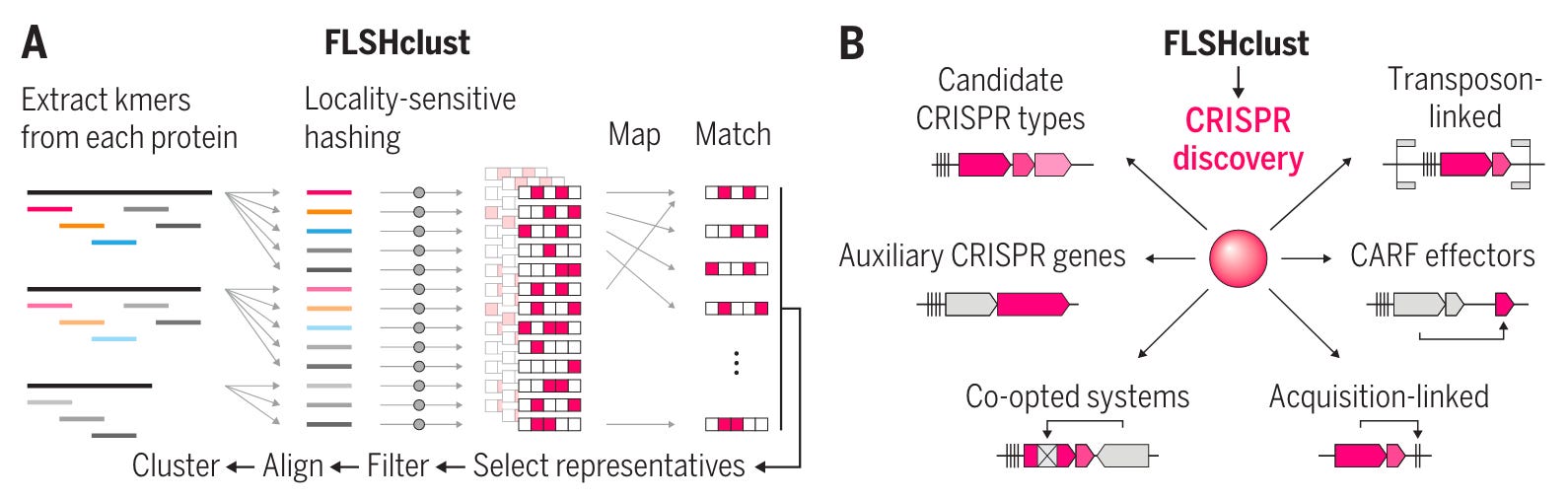
Why it matters: Systematic mining of nucleic acid and protein sequence databases has led to the discovery of protein family and functional systems like CRISPR. These outputs, in turn, have served as the basis for deep learning on protein sequences, protein structure prediction, and genome mining. Existing computational search methods rely on quadratic runtime (O(n²)), which are impractical for large datasets, or limit the ability to study deep evolutionary relationships. The authors have developed a method which performs clustering in linearithmic time (O(N logN)), making it a useful tool when mining large, exponentially increasing datasets.Feng Zhang’s lab et al. introduce locality-sensitive hashing–based clustering (FLSHclust) which performs deep clustering on massive datasets in linearithmic time. In order to overcome the limitation of quadratic runtime all-to-all comparisons, the team used locality-sensitive hashing (LSH), which groups similar, but not identical objects in linear time at the cost of false negatives and positives.
The authors used the algorithm in a CRISPR system discovery pipeline and identified 188 previously unreported CRISPR-linked gene modules.
Neuroinflammation: An astrocyte perspective [Lee et al., Science Trans Med, November 2023]
Why it matters: Astrocytes are the most abundant glial cell in the human brain, yet most of the recent focus in neurotherapeutics and glial cells has been on microglia. A comprehensive review in Science Translational Medicine discusses the role of astrocytes in disease, with a specific focus on diverse cell-astrocyte interactions, and their therapeutic potential. An exciting emerging class of therapeutics for neurodegenerative disease are drugs that target microglia, modulating the brain’s innate immune cells to normalize neuroinflammation and clear cellular debris. In addition to microglia, astrocytes are another type of glial cell that play an important role in neurodegenerative disease. Astrocytes perform a range of homeostatic functions, such as supporting other CNS-resident cells, buffering neurotransmitters, and regulating synaptic and blood-brain barrier function. In the context of neurodegenerative diseases like Alzheimer’s and Parkinson’s, astrocytes:
In response to pathological stimuli, astrocytes undergo a transformation known as "reactive astrogliosis." This process involves changes in morphology, genomic, metabolic, and functional features, potentially resulting in neurotoxic effects.
Astrocytes play crucial roles in neuronal development, synapse maturation, and synaptic transmission. For example, in MS and PD, reactive astrocytes lose the expression of glutamate reuptake transporters, resulting in increased concentrations of extracellular synaptic glutamate, which is toxic at high concentrations and results in neuronal cell death.
Diverse cell-cell interactions: Astrocytes regulate T cell migration and activation, and are involved in limiting proinflammatory T cell responses while promoting anti-inflammatory cell differentiation, interact with B cells, influencing their survival, activation, and antibody production, crucial in conditions like MS, and more. The review also discusses interactions between astrocytes and NK cells, microglia, and oligodendrocytes.
Translating knowledge of astrocyte neurobiology into novel drugs will require better understanding of complex cell-cell interactions (see figure below) and the role they play in disease. Technologies such as RABID-seq, SPEAC-seq, and spatial transcriptomics will be critical for mapping cell-cell interactions and the connectome (wiring diagram of neurons and glial cells).

Becoming fluent in proteins (IgLM, ProGen2)
Two recent papers showcase the emergence of protein language models (PLMs) - AI models that are trained to generate protein sequences with desired features. Two new PLMs:
ProGen2 - a very large, open source PLM that can generate full-length protein sequences. It can explore wide areas of sequence space while maintaining functional protein features. The researchers explore whether PLMs can be used zero-shot, i.e., without further training, for predicting the ‘‘fitness’’ of proteins
IgLM - a PLM specialised for antibody sequence design. It can generate antibody sequences and redesign antibody complementarity determining regions (CDRs). Shuai et al. show that the predicted CDRs explore a wide range of structural conformations and can even have desired properties such as improved solubility
Why it matters: These models are further testament to the new age of generative AI in protein design and engineering, where researchers can soon generate custom and diverse protein libraries completely in silico. Both models are open-source, allowing the community to further build on these innovations.Deep generative modeling of the human proteome reveals over a hundred novel genes involved in rare genetic disorders [Orenbuch et al., MedRxiv, November 2023]
Why it matters: The ability of popEVE to identify novel genes associated with rare genetic disorders could revolutionize the approach to diagnosing and treating these conditions. Traditionally, identifying the genetic basis of rare diseases has been challenging due to the need for repeated observations across large cohorts. popEVE overcomes this by providing a unified scale to evaluate the pathogenicity of variants, enabling the identification of disease-causing genes even in unique cases. This advancement not only accelerates the diagnostic process for rare genetic disorders but also opens new avenues for therapeutic development, potentially transforming the lives of patients with previously undiagnosed and untreated conditions.This study presents a significant advancement in genetic disease diagnosis and therapy development. Researchers developed a deep generative model, named popEVE, combining evolutionary information with population sequence data to achieve state-of-the-art performance in ranking genetic variants by severity. This helps distinguish patients with severe developmental disorders from potentially healthy individuals. popEVE identified 442 genes in a cohort of developmental disorder cases, providing evidence of 119 novel genetic disorders. This model offers a comprehensive perspective on the distribution of fitness effects across the entire proteome and the broader human population. It provides compelling evidence for genetic diagnoses in exceptionally rare single-patient disorders where conventional techniques may not be applicable. The model's interactive web viewer and downloads are available at pop.evemodel.org.
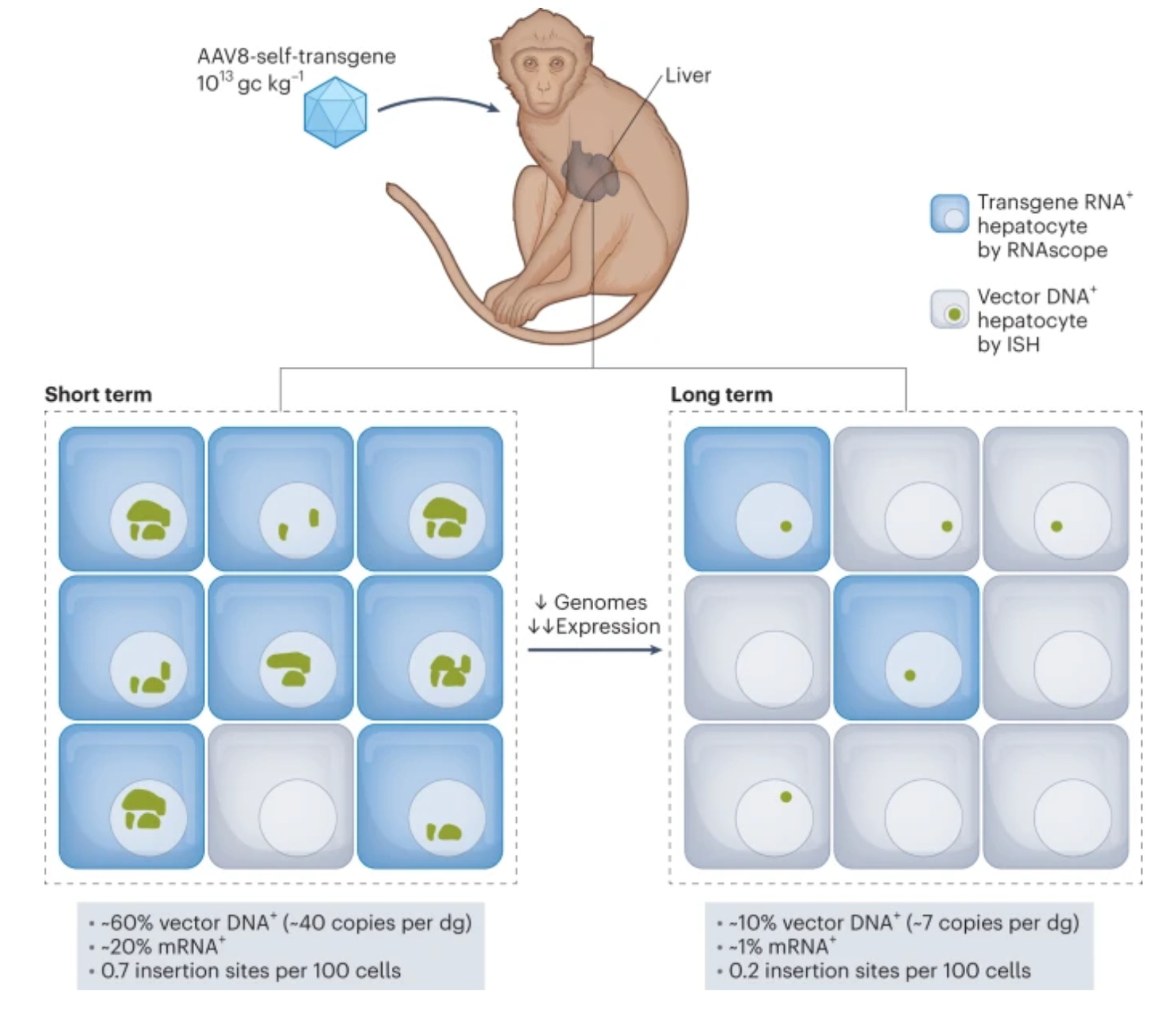
Integrated vector genomes may contribute to long-term expression in primate liver after AAV administration [Greig et al., Nature Biotechnology, 2023]
Why it matters: AAV is the vector de norme for gene therapy. However, the field has been plagued by concerns around the longevity and efficacy of said therapy over time. In this paper, Greig et al., probe AAV dynamics in nonhuman primates (NHPs) and establish that AAV-mediated transgene expression in hepatocytes occurs via 1) a “burst” of short-term episomal expression and 2) stable expression from possible integration into the native genome.AAV has been well established as the vector of choice for safe, efficacious, and long-term transgene expression. For example, various trials have reported AAV transgene longevity for up to 8 years in liver cells, with a satisfactory safety profile. However, the field has noticed a heterogeneity to AAV expression across patients. Generally speaking, there is an early expression peak within the first 6 months, followed by a reduction, either gradually or a marked decline with eventual stabilization. The mechanisms for this are likely a result of several factors, such as genetic cargo design, dose, serotype of vector, immunogenicity, and dose. However, it has been challenging to systematically assess the long-term fate of AAV within primary cells.
Here, the authors probe AAV8 transgene expression dynamics in 18 NHPs, each of which underwent four liver biopsies over two years. Using a variety of molecular techniques, including qPCR, single-nucleus RNA-seq, and in situ hybridization, the authors found that vector genomes decrease over time, along with corresponding RNA levels. Sequencing demonstrated that vector genomes underwent rearrangements and found integrated concatemerized (containing multiple copies of the same DNA linked in series) genomes two years after treatment, with only about 10-50% of them being intact sequences. Additionally, the amount of hepatocytes with vector DNA was up to 480-fold higher than those with vector RNA - suggesting that some form of epigenetic silencing was taking place, and that integrated genomes may be driving long-term expression. Interestingly, the authors found that hepatocytes contained discrete nuclear domains of vector DNA (almost like a biomolecular condensate) that persisted, similar to replication centers seen in other viral infections, such as adenovirus or herpes. This work is a welcome addition to the field of gene therapy, and sheds light on fundamental mechanisms which may be modulated to improve outcomes for these patients.
Notable Deals
Protein design software start-up raises $24M - still room for biotech saas business models

Cradle Bio has built an easy to use web-based software to design novel proteins with desired functions using generative AI, accessible to any scientist regardless of coding-literacy.
The company does not have its own pipeline (the traditional biotech business model) but charges companies to use its software and does not retain a stake in the projects it works on.
Given the explosion in recent open-sourced protein design tools (Chroma, RFDiffusion), it may seem difficult to build a long-standing business model based on software alone. Cradle argues there will always be a need for sleek front-ends to complicated models and a market for customers who would rather see the end product rather than utilise it themselves (hugging face has built a billion-dollar business on open-source for example). What’s more, the company generates its own data in house to finetune its models on specific use cases. However as frameworks such as Nvidia’s BioNeMo increase the accessibility of drug discovery models and pharma players push to build capabilities in-house, it will be interesting to see how company strategy such as Cradle’s changes into the future.
Bayer’s 12-year low and decade-long stock decline

Bayer has faced several shock stock drops for events such as Monsanto acquisition complications and recent asundexian phase III abandonment (a potential blockbuster, promising to bring peak sales of $5B). CEO Bill Anderson partly blames this gradual stock decline on a thin pipeline due to absence of a strong and focused R&D strategy by his predecessors.
“We had several years of under-investment up until about 2018. Bayer was not sourcing novel, cutting-edge molecules [and was not] going for really important targets,” Bill Anderson told the Financial Times. However the CEO promises a new strategy focusing on cell and gene therapy with billions of spend in BD will help turn the stock around.
Boehringer tests novel biology for $9M upfront
Phenomic AI has inked a target identification pact aimed at the tumour stroma with the German family-owned pharma. The upfront is relatively low and Boehringher will pay on success ($500M+ up for grabs).
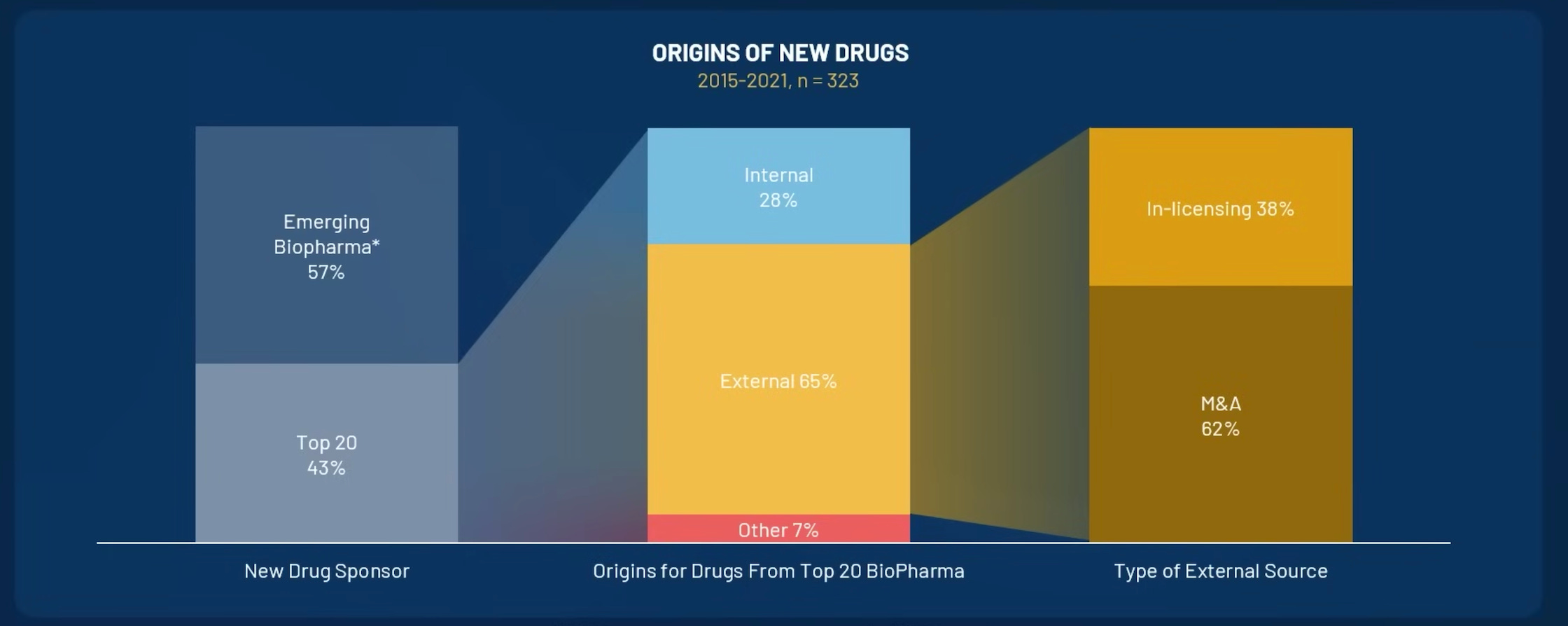
External innovation - key to replenish pharma pipelines
Pharma relies heavily on innovative biotech for 65% of their pipeline. Recent pharma deal activity (3Q22-2Q23) has leant towards small molecules and first-in-class therapies.

In case you missed it
Jason Wei of OpenAI gave a great presentation on “Some intuitions about large language models”

What we liked on X


Events

Field Trip
Did we miss anything? Would you like to contribute to Decoding Bio by writing a guest post? Drop us a note here or chat with us on Twitter: @zahrakhwaja @ameekapadia @ketanyerneni @morgancheatham @pablolubroth @patricksmalone
Love this week's set!