

Biobyte 058: Whole genome embryo reports, FDA raises concerns about CAR-T, scDREAMER for integrating single-cell sequencing datasets, the drawbacks of genomic deep learning to date, and more!
Biobyte 058: Whole genome embryo reports, FDA raises concerns about CAR-T, scDREAMER for integrating single-cell sequencing datasets, the drawbacks of genomic deep learning to date, and more!




Welcome to Decoding Bio, a writing collective focused on the latest scientific advancements, news, and people building at the intersection of tech x bio. If you’d like to connect or collaborate, please shoot us a note here or chat with us on Twitter: @zahrakhwaja @ameekapadia @ketanyerneni @morgancheatham @pablolubroth @patricksmalone. Happy decoding!

Winter is here. Luckily for you, we got some solid content this week. Print out this edition multiple times and stay warm as you sleep in Decoding Bio on this frigid winter night. Or light it on fire and breathe in some biology. Whatever you do, remember: learning by osmosis works, and don’t let anyone tell you otherwise.

What we read
Blogs
First Whole Genome Embryo Report [Orchid Health, December 2023]
Earlier this week, preimplantation genetic screening company Orchid announced the world’s first whole genome embryo reports will be available at IVF clinics around the US. Preimplantation genetic testing is a common procedure for screening embryos during the IVF process. Existing tests sequence <1% of the genome based on data from 4-6 cells taken from the embryo. Orchid’s new test sequences over 99% of the embryo’s genome which provides 100x the amount of data and insights into the embryo. These insights include things like genetic risk for certain diseases and specificity on genetic variants. Since the embryo report is released before that embryo is chosen to be transferred for pregnancy, Orchid’s technology allows for decisions to be made ahead of time, one of the only approaches that allows for this optionality. While the details of the approach are unclear, Orchid uses a combination of single-cell sequencing with bioinformatics tools and approaches including statistical genetics.
Trouble from CAR-T Treatment? [In the Pipeline, November 2023]
As many of you saw last week, the FDA announced they were investigating reports of T-cell malignancies being associated with the use of CAR-T cell therapy for other hematologic malignancies. As a reminder, CAR-T works by harvesting T-cells from patients, and genetically modifying them to express receptors that target antigens on said cancer cells. They are then expanded to significant numbers, before being infused back into patients, where they function as a living therapeutic - surveilling the body for cancer.
The FDA reports ~19 cases of T-cell lymphoma, which they believe may have been a function of engineered T-cells. It’s unclear what is the underlying cause, but we can certainly hypothesize: what if it was during the engineering phase - vectors may have integrated into the genome and caused the T-cells to become oncogenic. Were these wild-type malignancies manifesting after years of concurrent treatment with chemotherapies? Did patients have underlying somatic mutations in the engineered T-cells? We don’t have all the answers, and it will be important to see how this investigation turns out; the results may well change how we approach this entire modality.
Propaganda or Science: A Look at Open Source AI and Bioterrorism Risk [Less Wrong, November 2023]
In a detailed analysis of the evidence presented in policy papers advocating for the ban of open source large language models (LLMs) due to bioterrorism risks, the review finds a significant gap between the evidence cited and the conclusions drawn. The primary evidence from Anthropic is based on inaccessible data and personal interpretations, while other citations rely heavily on a single, flawed experiment lacking a control group. This creates an illusion of substantial evidence when, in reality, there is little to support the claim that open source LLMs pose a significant bioterrorism risk.
The review also introduces two principles to assess the potential bioterrorism risks of LLMs: the Principle of Substitution, which requires evidence that LLMs provide unique information not accessible through other means like the internet or textbooks, and the Blocker Principle, which looks for evidence that the absence of LLM-provided information significantly hinders bioweapon creation. The review argues that the current discourse fails to seriously engage with these principles, often overlooking the broader context in which LLMs operate and the relative impact they have in the complex process of bioweapon creation.
Additionally, the review points out that most of the questionable research is funded by Open Philanthropy, suggesting a potential bias towards producing results that align with their preconceived stance against open source LLMs. This pattern raises concerns about the objectivity and integrity of the research in this field. The review concludes that the current state of evidence does not justify a policy of criminalizing open source LLMs due to bioterrorism risks, emphasizing the need for more rigorous, unbiased research to inform such significant policy decisions.
Academic papers
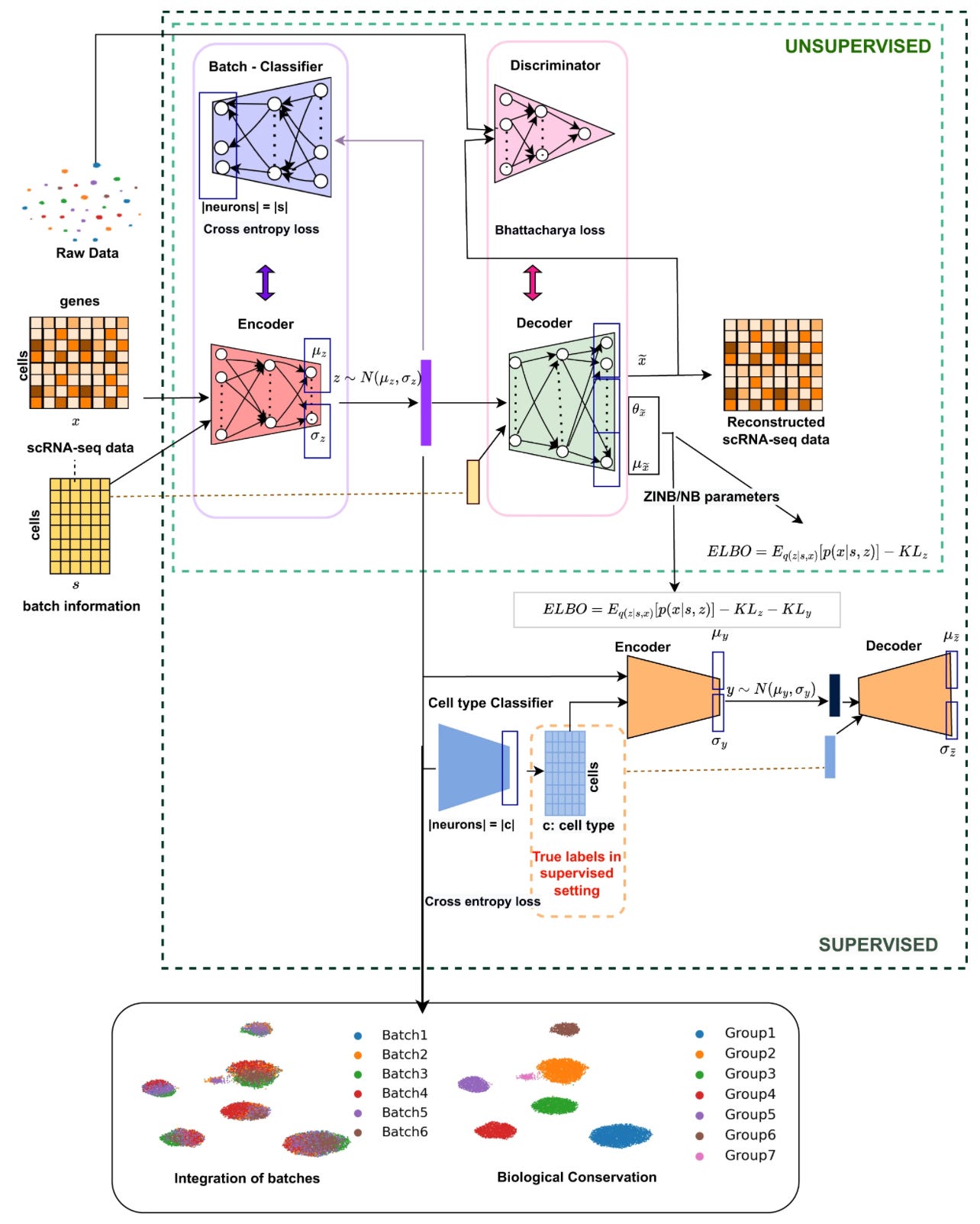
Why it matters: The integration of as much single-cell sequencing datasets into biological models is crucial for attempting to unravel the inherent complexity of biology. However, different datasets are confounded with experimental differences that can create complex, nested batch effects that can diminish the value of data integration by confounding biological signals.Shree et al introduce a deep generative model framework that integrates multiple heterogeneous single-cell datasets across many tissues in an unsupervised manner. scDREAMER employs an adversarial variational autoencoder for learning the lower-dimensional representation of cells from the high-dimensional scRNA-seq data and a neural network classifier for the removal of batch effects. It can overcome typical challenges such as batch effects and the need for cell type annotations.
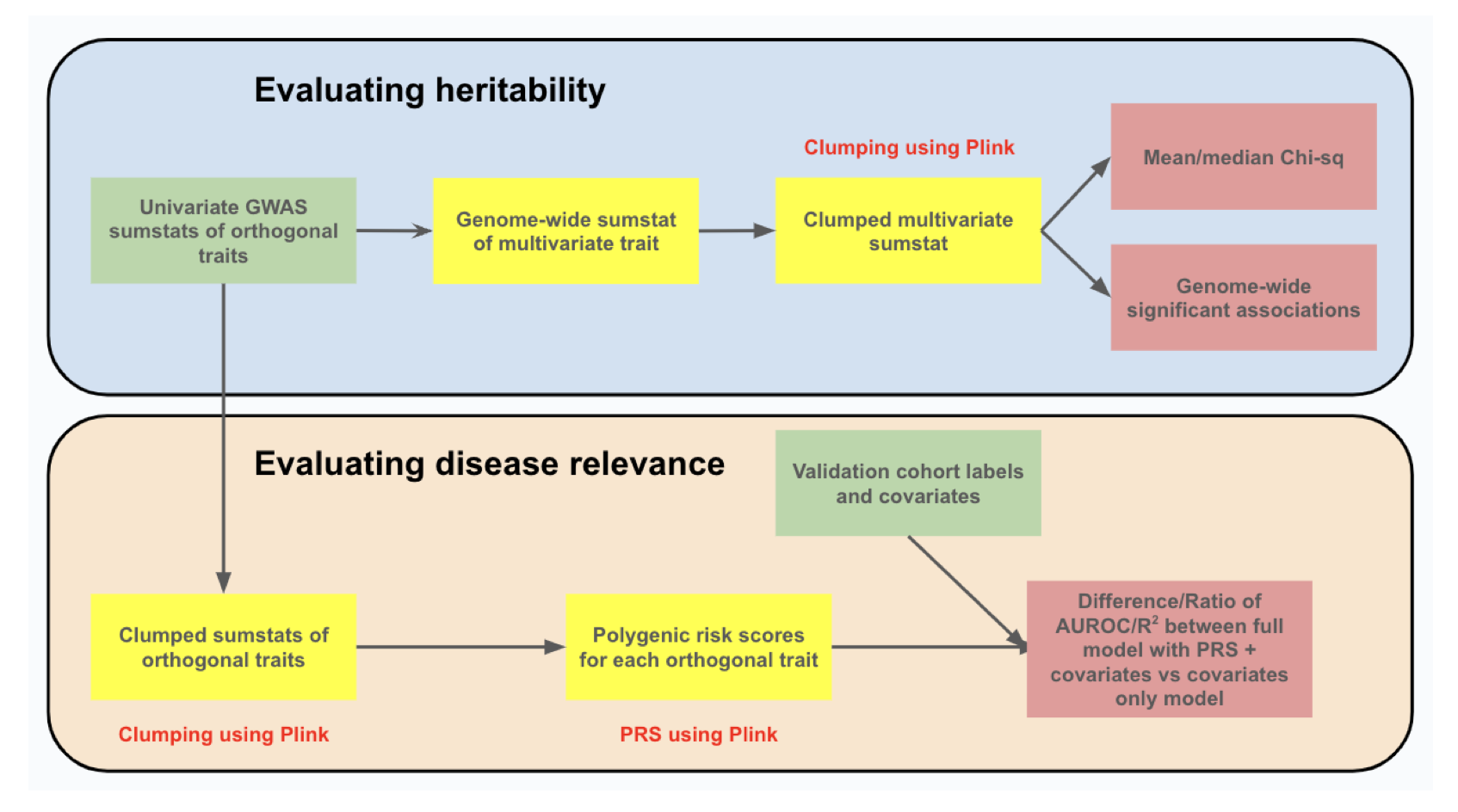
EmbedGEM: A framework to evaluate the utility of embeddings for genetic discovery [Mukherjee et al., bioRxiv, 2023]
Why it matters: Embeddings derived from deep learning models are hypothesized to capture disease state information which could be useful in genetic discovery. Embeddings, however, are often confounded by covariates and their relevance to disease is difficult to confirm. Systematic evaluation of the relevance of embeddings to disease could help link new relevant variants to disease indications of interest.The authors developed EmbedGEN (Embedding Genetic Evaluation Methods) which compares embeddings along two axes i) heritability and ii) ability to identify disease relevant variants. Heritability was assessed using mean/median Chi-squared statistic and genome-wide significant associations. To evaluate disease relevance, EmbedGEN computes polygenic risk scores (PRS) for each orthogonal component of the embedding and evaluates relevance when compared to patients with high-confidence disease traits. EmbedGEN successfully ranked the simulated traits and demonstrated utility on data from the UK Biobank.
Current approaches to genomic deep learning struggle to fully capture human genetic variation [Tang et al., Nature Genetics, November 2023]
Why it matters: Deep learning models for predicting gene expression on the basis of DNA sequence have advanced considerably in recent years, however a pair of recent Nature Genetics papers found that state-of-the-art models struggle to correctly predict the directionality (increase vs decrease) of expression changes from single nucleotide variants (SNVs). If models incorrectly predict whether a variant will increase or decrease expression, this will limit their usefulness for tailoring treatments or making health risk assessments based on a patient's genetics.This recent Letter published in Nature Genetics discusses important limitations in the ability of current state-of-the-art genomic deep learning models such as Enformer to accurately predict the effects of genetic variation on gene expression. Two recent studies in Nature Genetics (Sasse et al. and Huang et al.) found that models like Enformer struggle to correctly predict the directionality (increase vs decrease) of expression changes from single nucleotide variants (SNVs), although, surprisingly, they capture the magnitude of changes reasonably well (see figure below for example genes). The reasons why deep learning models fail to capture regulatory variant effects are still unclear - possible factors like SNV location, expression quantitative trait loci (eQTL) effect size, etc. could not fully explain the poor performance. The authors propose training on more diverse genomes to learn a more comprehensive set of regulatory features that are missed when training on a single reference genome, and incorporating biological priors like post-transcriptional regulation to improve variant effect prediction.

A network-based normalized impact measure reveals successful periods of scientific discovery across discipline [Ke et al., PNAS, October 2023]
Why it matters: The new network-based methodology for evaluating scientific impact is significant for its contribution to a fairer and more balanced assessment of scientific achievements. This approach transcends traditional citation count metrics, which are often biased towards certain fields, and instead offers a normalized measure that equitably compares research impact across diverse disciplines. By doing so, it highlights significant contributions from fields that are typically underrepresented in citation-based evaluations.This paper introduces a novel methodology for evaluating the impact of scientific publications. Traditionally, the impact of a scientific paper is gauged by its citation count, but this approach is limited by variations in citation practices across different fields and times, making it challenging to compare scientific achievements fairly. The authors propose a network-based approach to normalize citation counts, which eliminates the need for predefined discipline labels and compares a paper's impact with locally similar research. This method corrects for biases related to the field and time of publication, offering a more equitable way to assess scientific impact.

Using this new measure, the authors analyze the evolution of science, identifying key research fields and periods of high-impact discoveries. Their results highlight significant contributions from diverse fields beyond the traditionally citation-rich biomedical sciences, such as geosciences, radiology, and optics. The study provides valuable insights into the dynamics of scientific breakthroughs and offers a more balanced perspective on the contributions of various scientific disciplines. This approach paves the way for fairer comparisons of scientific impact across different fields and time periods, contributing significantly to the science of science and bibliometric analyses.
Notable Deals
AbbVie acquires commercial ADC player Immunogen for $10.1B
The acquisition comes at a 95% premium which is particularly substantial in the current market. Immunogen’s central asset is ADC Elahere, approved in 2022 for advanced ovarian cancer and largely commercially derisked. Although Abbvie typically plays in the heme-onc space, Elahere will increase its topline substantially in the coming years.
Roche enters GLP-1 space via $2.7B acquisition of Carmot Therapeutics
The Swiss pharma is paying $2.7bn + $400M in milestones for Carmot’s incretin pipeline. Carmot has 3 assets in the clinic and was valuable at $1.25B during its latest raise. Carmot chose M&A over an IPO which strategically makes sense due to the complexity and cost surrounding GLP-1 drug manufacture and commercialisation, where Lilly and Novo are rapidly advancing.
Absci’s reals in AstraZeneca and Allmirall
The publicly-traded generative AI biologics company has announced a $247M total biobucks deal with AstraZeneca to design an antibody against an undisclosed oncology indication. The collaboration with Absci is part of AstraZeneca’s plan to enhance the diversity and efficacy of the biologics they discover.
Absci has also announced a collaboration with Almirall worth $650M and helps expand Absci’s presence in dermatology.
Sanofi announces its sixth AI-driven partnership with Aqemia
The french pharma will pay up to $140 million to Paris-based start-up as part of a multi-year collaboration for a number of small molecules using technology combining quantum-inspired physics and machine learning. Sanofi will be solely responsible for wet lab research, development and commercialisation activities, partly explaining the relatively small deal size.
Seismic raises a $121M Series B to tackle immunology with ML
The raise comes at a clear value inflection point for the AI biotech, with its two lead biologics in IND-enabling studies after only 18 months since launch.
Odyssey Therapeutics raises $101M in a new round
The small molecule biotech led by Gary Glick aims to have three drugs in the clinic in 2024. It disclosed parts of its pipeline of high value oncology (CDK2) and immunology assets (RIPK2, IRAK4) earlier this year.
What we listened to
In case you missed it

What we liked on socials channels
Why Moore’s law will eat Eroom’s law
Some takeaways from Machine Learning in Computational Biology
Jensen Huang, CEO and founder of Nvidia, bets on digital biology
Why being first-in-class matters
Field Trip
Did we miss anything? Would you like to contribute to Decoding Bio by writing a guest post? Drop us a note here or chat with us on Twitter: @ameekapadia @ketanyerneni @morgancheatham @pablolubroth @patricksmalone